Pythonを使用したスクレイピングでGoogle画像検索ページから画像を取得することができたので解説してみます。取得する画像はリンク先の元画像です。
目次
はじめに
Pythonはこれまで見たこともなかったのですが、YoutubeでPythonスクレイピングの動画をなにげに見てみたらおもしろそうだったのでやってみました。YoutubeとWeb記事のみを利用した独学でPython歴2か月未満のため記述や解釈などに間違いがあるかもしれません。その点ご留意ください。
参考にした情報
スクレイピング動画
キノコード
https://www.youtube.com/channel/UCGlgXjYVoHLD86TQQ799WIw
直也テック
https://www.youtube.com/channel/UCNfkZH_yEucwJFyl_R3EfjA
Python
@IT – Python入門
https://www.atmarkit.co.jp/ait/subtop/features/di/pybasic_index.html
note.nkmk.me – Python関連記事まとめ
https://note.nkmk.me/python-post-summary/
CODEPREP(学習サービス)
https://codeprep.jp/
Selenium
公式
https://www.selenium.dev/
https://www.selenium.dev/documentation/ja/ (日本語)
https://www.selenium.dev/selenium/docs/api/py/api.html
Baiju Muthukadan著
https://selenium-python.readthedocs.io/
https://kurozumi.github.io/selenium-python/index.html (日本語)
Seleniumクイックリファレンス
https://www.seleniumqref.com/
Requests
公式
https://requests.readthedocs.io/en/latest/
https://requests-docs-ja.readthedocs.io/en/latest/ (日本語・バージョン古い)
Beautiful Soup(今回は未使用)
公式
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
http://kondou.com/BS4/ (日本語・バージョン古い)
スクレイピングの注意点
スクレイピングを行う場合は法律上の問題点について理解しておいたほうがいいようです。以下のサイトで詳しく解説されています。
スクレイピングは違法?3つの法律問題と対応策を弁護士が5分で解説
まとめの部分を引用します。
https://topcourt-law.com/internet_security/scraping-illegal#i-17
- 「スクレイピング」とは、ウェブサイトからHTMLの情報を取得して、取得した情報の中から使いたい情報を抽出し、自社の目的に合った使い方ができるように形を整えなおすことをいう
- スクレイピングについて法律上問題となるのは、①著作権法上の問題、②利用規約との抵触、③サーバーへの過度なアクセスの3つである
- コンピュータによって情報を解析することが目的である場合には、著作権者の同意を得ることなく、スクレイピングによって取得した他社情報などを記録媒体に記録したり翻案することができる
- 適切にスクレイピングを行うためには、①利用目的、②スクレイピングの対象、③アクセス制限の遵守、④利用規約を注意しておく必要がある
開発環境
| OS | Windows 10 |
| Python | 3.7.6 |
| Selenium | 3.141.0 |
| Google Chrome | 84.0.4147.89 |
| ChromeDriver | 84.0.4147.30 |
ソースコード解説
概要
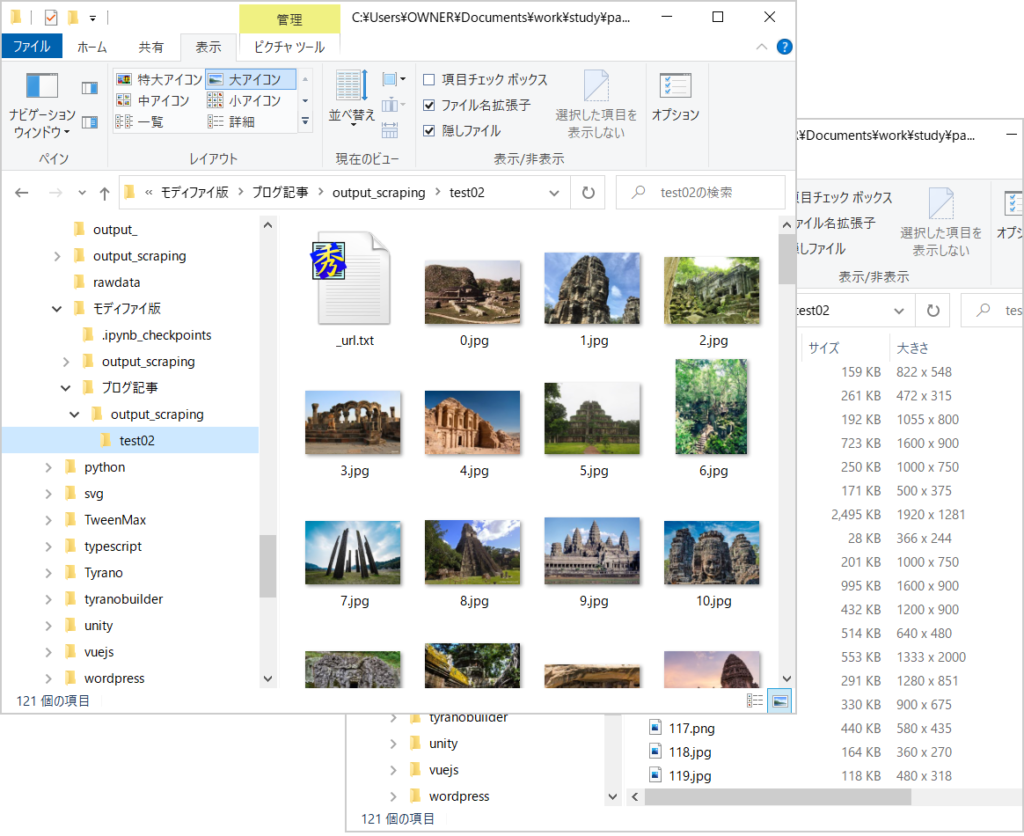
- Google画像検索を行うとサムネイル画像が表示されます。これらの画像はBase64の埋め込みデータだったり、https://encrypted-tbn0.gstatic.com/やhttps://lh3.googleusercontent.com/といったサイトにアップされている(ファイル名がハッシュ値っぽい)画像だったりします。この画像(①)をクリックするとウィンドウが二分され、右上に大きめの画像(②)が表示されます。この画像のsrc属性に設定されているurlを取得して元画像をダウンロードします。
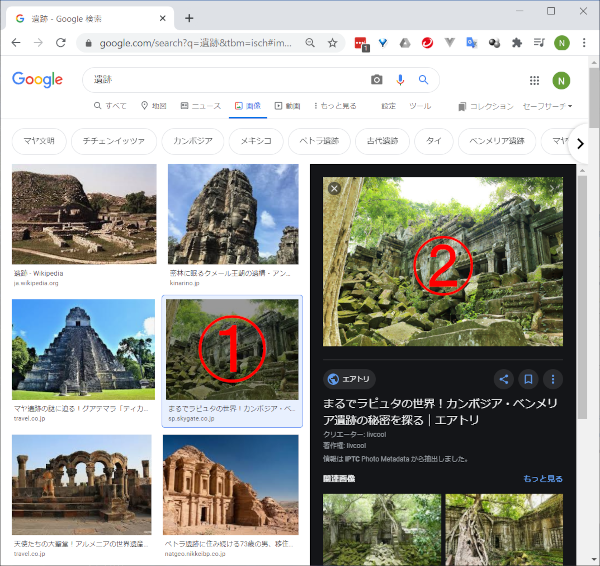
- はじめにサムネイル画像(①)をまとめて取得します。取得したい枚数分の画像が表示されるまでウィンドウをスクロールしてから取得します。
- 次に、取得したサムネイル画像(①)のクリックと、クリックにより表示される画像(②)のダウンロードを繰り返し行います。ここで、②の画像の特定とurlの取得のしかたが重要になります。コードとともに後述します。
ポイント解説
全ソースコードからスクレイピングに関する部分を抜粋して解説します。
インポート
インポートする主なモジュールは以下のとおりです。Beautiful SoupやSeleniumのWebDriverWaitは作り始めの頃は利用していたのですが、最終的に本プログラムでは不要となり外しました。
import time
import requests
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import ElementClickInterceptedException
Chrome起動
SeleniumのWebDriverからChromeブラウザをヘッドレスモードで起動します。起動オプションをいろいろ試してみたのですが、スクレイピング処理への影響は正直分かりませんでした(–headless だけでもよさそうでした)。現在の設定を懸案事項として記載しておきます。起動オプションについてはこちらを参照ください。
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
# options.add_argument('--start-maximized')
options.add_argument('--start-fullscreen')
options.add_argument('--disable-plugins')
options.add_argument('--disable-extensions')
driver = webdriver.Chrome(DRIVER_PATH, options=options)
サムネイル画像の取得
SeleniumのCSSセレクタを利用してサムネイル画像を取得します。ID名がislmpのdiv要素を起点にしています。
tmb_elems = driver.find_elements_by_css_selector('#islmp img')
この方法では関連キーワードの小さな画像も取得されます。この不要な画像とサムネイル画像はalt属性値が空かどうかで判別します。
# サムネイル画像の数を知りたい場合
tmb_alts = [tmb.get_attribute('alt') for tmb in tmb_elems]
count = len(tmb_alts) - tmb_alts.count('')
# サムネイル画像だけ処理したい場合
for tmb_elem, tmb_alt in zip(tmb_elems, tmb_alts):
if tmb_alt == '':
continue
処理
Memo
他の方法として、サムネイル画像に付与されているクラス名 rg_i と Q4LuWd を利用して取得することもできます。この場合は関連キーワードの画像が除外されるので前述の方法よりも記述がシンプルになります。今回はこのクラスの名前が意味のあるものに見えなかった(自動生成っぽい?)ので安定性を考えて前述の方法にしました。
Google画像検索のページを下方向にスクロールさせると新しい画像が読み込まれ、より多くの画像を取得できるようになります。スクロールはSelenium WebDriverのexecute_scriptメソッドからJavaScriptのスクロールメソッドを実行させて行います。
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
- ページの一番下にスクロールする方法は? – Selenium Python Bindings
- execute_script – Selenium 3.14 documentation
- scrollTo – MDN
Memo
スクロールさせた後に画像を取得する場合、画像の読み込みが完了するまでウェイトする必要があります。このウェイトを
WebDriverWait(driver, TIMEOUT) .until(EC.presence_of_all_elements_located)
で行うとスクロール前と同じ内容が取得されるケースがあったので、今回は
time.sleep(1)
で行うことにしました。
サムネイル画像のクリック
サムネイル画像のクリックはSelenium WebElementのclickメソッドで行います。サムネイル画像がウィンドウの表示領域から外れている場合は例外が発生するので、例外処理のなかでサムネイル画像を表示領域内にスクロールし、再度クリックするようにしています。execute_scriptは先ほども利用しましたが、ここでは第二引数にElementオブジェクトを渡すことでElementオブジェクトのメソッドであるscrollIntoViewを呼び出しています。
RETRY_NUM = 3 # リトライ回数
for i in range(RETRY_NUM):
try:
tmb_elem.click()
except ElementClickInterceptedException:
driver.execute_script('arguments[0].scrollIntoView(true);', tmb_elem)
time.sleep(1)
else:
break
else:
continue
ダウンロード対象画像の特定
サムネイル画像をクリックすると表示される領域(②を含む右側の領域)を取得します。ID名がislspのdiv要素です。
imgframe_elem = driver.find_element_by_id('islsp')
上記のdiv要素を起点に、SeleniumのCSSセレクタを利用してサムネイル画像に付与されているalt属性値と同じ値を持つimg要素を探します。
# tmb_alts = [tmb.get_attribute('alt') for tmb in tmb_elems]
# for tmb_elem, tmb_alt in zip(tmb_elems, tmb_alts):
alt = tmb_alt.replace("'", "\\'")
try:
img_elem = imgframe_elem.find_element_by_css_selector(f'img[alt=\'{alt}\']')
except NoSuchElementException:
continue
Memo
- WebDriverでID名がislspの要素を見つけ、そこからWebElementで検索範囲を狭めて検索を行っています。たしかJavaScriptではこういったことをするとトータルで遅くなるような気がしたのですが、Seleniumの公式ドキュメントに載っていたので使いました。
https://www.selenium.dev/documentation/ja/getting_started_with_webdriver/locating_elements/ - alt属性値をエスケープ処理しないと「Let’s」などの文字がある場合にInvalidSelectorExceptionの例外が発生します。
- 本プログラムでは現在Google画像検索ページで使われているID名islmpとislspを利用しています。これらのID名は今後変わる可能性がありますのでご留意ください。
urlの取得
ダウンロード対象画像のimg要素を取得できたので、このimg要素のsrc属性を読み出してurlを取得します。ここで注意点があります。本プログラムをデバッグしていて気が付いたのですが、サムネイル画像をクリックするとダウンロード対象画像のsrc属性には初期値としてサムネイル画像と同じ値が設定されるようです。そして、サムネイル画像を表示しつつ裏でこっそり元画像の読み込みを行い、最終的に画像とsrc属性値が元画像のものに書き換わるような動作になっています。
つまり、クリック後に元画像の読み込み完了を待たずにsrc属性値を読み出すとサムネイル画像のurlが取得されてしまうことになります。このsrc属性値の変化を捉えることができればいいのですが、img要素自体はすでにlocatedでありvisibleでありclickableであるためWebDriverWaitメソッドでは捉えられませんでした。
そこで、本プログラムでは取得したsrc属性値をサムネイル画像のsrc属性値と比較して値が異なっていたら元画像のurlであると判断することにしました。
また、画像サイズが小さかったり拡張子がないという理由でhttps://lh3.googleusercontent.com/上の画像をダウンロード対象外にしました。
EXCLUSION_URL = 'https://lh3.googleusercontent.com/' # 除外対象url
tmb_url = tmb_elem.get_attribute('src') # サムネイル画像のsrc属性値
for i in range(RETRY_NUM):
url = img_elem.get_attribute('src')
if EXCLUSION_URL in url:
url = ''
break
elif url == tmb_url: # src属性値が遷移するまでリトライ
time.sleep(1)
url = ''
else:
break
if url == '':
continue
Memo
ダウンロード対象画像のsrc属性値の変化例を示します。
src="data:image/jpeg;base64,/9j/4AAQSkZJR ..." ↓ src="https://.../.../xxx.jpg"
src="https://encrypted-tbn0.gstatic.com/images?q=...&usqp=CAU" ↓ src="https://.../cms/wp-content/uploads/xxx.jpg"
urlのチェック
拡張子がない画像データに拡張子としてjpgを付けて保存してもエクスプローラーでプレビュー表示できたり画像ソフトで開けたりすることもありますが、本プログラムでは拡張子がない場合はダウンロードしないことにしました。
また、pngファイルの中身を読み出して拡張子をjpgとして保存した場合も同様に問題ないようにみえますが、本プログラムではファイル構造と拡張子がずれないように拡張子を元画像と同じにしています。
IMG_EXTS = ('.jpg', '.jpeg', '.png', '.gif') # ダウンロード対象のファイル拡張子
def get_extension(url):
url_lower = url.lower()
for img_ext in IMG_EXTS:
if img_ext in url_lower:
extension = '.jpg' if img_ext == '.jpeg' else img_ext
break
else:
extension = ''
return extension
ext = get_extension(url)
if ext == '':
continue # urlに拡張子が含まれていないのでキャンセル
# 保存するファイル名
filename = f'{FILE_NAME}{count}{ext}'
ダウンロード
requestsモジュールを利用してurlの画像を取得します。本プログラムでは以下のように記述しています。
requests.get(url, headers=HTTP_HEADERS, stream=True, timeout=10)
Memo
実はこの記述ではSSLErrorの例外が発生します。
SSLError: HTTPSConnectionPool(host='www.hirosaki.u-coop.or.jp', port=443): Max retries exceeded with url: /shopping/apple/images/2019_apple02.jpg (Caused by SSLError(SSLError("bad handshake: Error([('SSL routines', 'tls_process_server_certificate', 'certificate verify failed')])")))
この例外はverify=Falseを設定すると発生しなくなります(InsecureRequestWarningは発生しますがちゃんとurlのページを取得できます)。
requests.get(url, headers=HTTP_HEADERS, stream=True, timeout=10, verify=False)
本プログラムではセキュリティ面を考慮してSSL認証できないサーバにはアクセスしないことにしました。SSLErrorは例外処理で受け流し次の画像を処理するようにしています。
ここで、サーバに認証が拒否されて403 Client Errorが発生する場合があります。これは、HTTPヘッダのUser-Agentを設定することで解消しました。execute_scriptメソッドでJavaScriptのnavigator.userAgentの値を取得し設定します。
HTTP_HEADERS = {'User-Agent': driver.execute_script('return navigator.userAgent;')}
print(HTTP_HEADERS)
# {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) HeadlessChrome/84.0.4147.125 Safari/537.36'}
取得した画像データをファイルへ保存します。open関数はPythonの組み込み関数で、バイナリモードで利用します。実際のソースコードは以下のようになります。
def download_image(url, path, loop):
result = False
for i in range(loop):
try:
r = requests.get(url, headers=HTTP_HEADERS, stream=True, timeout=10)
r.raise_for_status()
with open(path, 'wb') as f:
f.write(r.content)
except requests.exceptions.SSLError:
print('***** SSL エラー')
break
except requests.exceptions.RequestException as e:
time.sleep(1)
else:
result = True
break
return result
result = download_image(url, path, RETRY_NUM)
if result == False:
continue
雑記
- 本プログラムではサムネイル画像をクリックした後、ダウンロード対象画像のsrc属性値が変化するまでsleepを挟みながらループします。sleep時間やループ回数を増やすと画像の取得率が上がりますが、なかにはsrc属性値が変化しないものもあり、これにあたるとトータルで時間がとてもかかってしまいます。このためsleep時間やループ回数を増やし過ぎないようにしてsrc属性値が変化しなかったものは捨てるほうが画像収集効率がいいと感じました(小さい画像でもいい場合はそのまま取得してもいいと思います)。
- エラーや例外が発生してもスクレイピング処理を止めないことが大切だと思います。一度止まると最初からになってしまいますから。ですのでエラー処理や例外処理はしっかり記述したほうがいいと思います。
- スクレイピングの注意点にありますが、一般的にサーバーへの過度なアクセスを避けるためループ処理のなかでsleepすることになると思います。ですのでループ処理内での要素検出等の処理速度はあまり気にしなくていいと思います。
- Google画像検索のページで使われているID名やクラス名がいまいち信用できないためimg要素を見つけるのに苦労しました。以下に現在使われていて関係のありそうなものをまとめておきます。
| ID名 | islmp | サムネイル画像の表示領域(div) | 今回使用 |
| islsp | ダウンロード対象画像を含む右側の領域(div) | 今回使用 | |
| クラス名 | rg_i Q4LuWd | サムネイル画像に付与されているクラス名(img) | 今回未使用 |
| n3VNCb | ダウンロード対象画像に付与されているクラス名(img) | 今回未使用。前後のサムネイル画像にも付与。src属性値で判別可。 |
- 最後にPythonでひっかかったところをメモっておきます。
x = 10
def bar():
print(x)
bar()
上記のコードを実行すると10が表示されます。では以下のコードを実行するとどうなるでしょう。
x = 10
def foo():
print(x)
x += 1
foo()
このコードを実行するとUnboundLocalErrorになります。解説はこちら。
全ソースコード
import requests
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import os
import time
import datetime
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import ElementClickInterceptedException
tm_start = time.time() # 処理時間計測用
dt_now = datetime.datetime.now() # 現在日時
dt_date_str = dt_now.strftime('%Y/%m/%d %H:%M')
print(dt_date_str)
QUERY = '遺跡' # 検索ワード
LIMIT_DL_NUM = 120 # ダウンロード数の上限
SAVE_DIR = 'output_scraping/test01' # 出力フォルダへのパス(フォルダがない場合は自動生成する)
FILE_NAME = '' # ファイル名(ファイル名の後ろに0からの連番と拡張子が付く)
TIMEOUT = 60 # 要素検索のタイムアウト(秒)
ACCESS_WAIT = 1 # アクセスする間隔(秒)
RETRY_NUM = 3 # リトライ回数(クリック、requests)
DRIVER_PATH = '../chromedriver' # chromedriver.exeへのパス
# Chromeをヘッドレスモードで起動
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
# options.add_argument('--start-maximized')
options.add_argument('--start-fullscreen')
options.add_argument('--disable-plugins')
options.add_argument('--disable-extensions')
driver = webdriver.Chrome(DRIVER_PATH, options=options)
# タイムアウト設定
driver.implicitly_wait(TIMEOUT)
tm_driver = time.time()
print('WebDriver起動完了', f'{tm_driver - tm_start:.1f}s')
# Google画像検索ページを取得
url = f'https://www.google.com/search?q={QUERY}&tbm=isch'
driver.get(url)
tm_geturl = time.time()
print('Google画像検索ページ取得', f'{tm_geturl - tm_driver:.1f}s')
tmb_elems = driver.find_elements_by_css_selector('#islmp img')
tmb_alts = [tmb.get_attribute('alt') for tmb in tmb_elems]
count = len(tmb_alts) - tmb_alts.count('')
print(count)
while count < LIMIT_DL_NUM:
# ページの一番下へスクロールして新しいサムネイル画像を表示させる
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(1)
# サムネイル画像取得
tmb_elems = driver.find_elements_by_css_selector('#islmp img')
tmb_alts = [tmb.get_attribute('alt') for tmb in tmb_elems]
count = len(tmb_alts) - tmb_alts.count('')
print(count)
# サムネイル画像をクリックすると表示される領域を取得
imgframe_elem = driver.find_element_by_id('islsp')
# 出力フォルダ作成
os.makedirs(SAVE_DIR, exist_ok=True)
# HTTPヘッダ作成
HTTP_HEADERS = {'User-Agent': driver.execute_script('return navigator.userAgent;')}
print(HTTP_HEADERS)
# ダウンロード対象のファイル拡張子
IMG_EXTS = ('.jpg', '.jpeg', '.png', '.gif')
# 拡張子を取得
def get_extension(url):
url_lower = url.lower()
for img_ext in IMG_EXTS:
if img_ext in url_lower:
extension = '.jpg' if img_ext == '.jpeg' else img_ext
break
else:
extension = ''
return extension
# urlの画像を取得しファイルへ書き込む
def download_image(url, path, loop):
result = False
for i in range(loop):
try:
r = requests.get(url, headers=HTTP_HEADERS, stream=True, timeout=10)
r.raise_for_status()
with open(path, 'wb') as f:
f.write(r.content)
except requests.exceptions.SSLError:
print('***** SSL エラー')
break # リトライしない
except requests.exceptions.RequestException as e:
print(f'***** requests エラー({e}): {i + 1}/{RETRY_NUM}')
time.sleep(1)
else:
result = True
break # try成功
return result
tm_thumbnails = time.time()
print('サムネイル画像取得', f'{tm_thumbnails - tm_geturl:.1f}s')
# ダウンロード
EXCLUSION_URL = 'https://lh3.googleusercontent.com/' # 除外対象url
count = 0
url_list = []
for tmb_elem, tmb_alt in zip(tmb_elems, tmb_alts):
if tmb_alt == '':
continue
print(f'{count}: {tmb_alt}')
for i in range(RETRY_NUM):
try:
# サムネイル画像をクリック
tmb_elem.click()
except ElementClickInterceptedException:
print(f'***** click エラー: {i + 1}/{RETRY_NUM}')
driver.execute_script('arguments[0].scrollIntoView(true);', tmb_elem)
time.sleep(1)
else:
break # try成功
else:
print('***** キャンセル')
continue # リトライ失敗
# アクセス負荷軽減用のウェイト
time.sleep(ACCESS_WAIT)
alt = tmb_alt.replace("'", "\\'")
try:
img_elem = imgframe_elem.find_element_by_css_selector(f'img[alt=\'{alt}\']')
except NoSuchElementException:
print('***** img要素検索エラー')
print('***** キャンセル')
continue
# url取得
tmb_url = tmb_elem.get_attribute('src') # サムネイル画像のsrc属性値
for i in range(RETRY_NUM):
url = img_elem.get_attribute('src')
if EXCLUSION_URL in url:
print('***** 除外対象url')
url = ''
break
elif url == tmb_url: # src属性値が遷移するまでリトライ
print(f'***** urlチェック: {i + 1}/{RETRY_NUM}')
# print(f'***** {url}')
time.sleep(1)
url = ''
else:
break
if url == '':
print('***** キャンセル')
continue
# print(f'url: {url}')
# 画像を取得しファイルへ保存
ext = get_extension(url)
if ext == '':
print(f'***** urlに拡張子が含まれていないのでキャンセル')
print(f'{url}')
continue
filename = f'{FILE_NAME}{count}{ext}'
path = SAVE_DIR + '/' + filename
result = download_image(url, path, RETRY_NUM)
if result == False:
print('***** キャンセル')
continue
url_list.append(f'{filename}: {url}')
# ダウンロード数の更新と終了判定
count += 1
# print(f'\r{count}/{LIMIT_DL_NUM}', end='') # 進捗表示
if count >= LIMIT_DL_NUM:
# time.sleep(1) # 進捗表示ウェイト
# print(f'\r{" " * 7}\r', end='') # 進捗非表示
break
tm_end = time.time()
print('ダウンロード', f'{tm_end - tm_thumbnails:.1f}s')
print('------------------------------------')
total = tm_end - tm_start
total_str = f'トータル時間: {total:.1f}s({total/60:.2f}min)'
count_str = f'ダウンロード数: {count}'
print(total_str)
print(count_str)
# urlをファイルへ保存
path = SAVE_DIR + '/' + '_url.txt'
with open(path, 'w', encoding='utf-8') as f:
f.write(dt_date_str + '\n')
f.write(total_str + '\n')
f.write(count_str + '\n')
f.write('\n'.join(url_list))
driver.quit()